GAN model Training(fit)_with Giovanni
#device name
import tensorflow as tf
if tf.config.list_physical_devices('GPU'):
device_name=tf.test.gpu_device_name()
else:
device_name='/CPU:0'
import time
num_epochs=100
batch_size=64
image_size=(28, 28)
z_size=20
mode_z='uniform'
gen_hidden_layers=1
gen_hidden_size=100
disc_hidden_layers=1
disc_hidden_size=100
tf.random.set_seed(1)
np.random.seed(1)
if mode_z=='uniform':
fixed_z=tf.random.uniform(shape=(batch_size, z_size), minval=-1, maxval=1)
elif mode_z=='normal':
fixed_z=tf.random.normal(shape=(batch_size, z_size))
def create_samples(g_model, input_z):
g_output=g_model(input_z, training=False)
images=tf.reshape(g_output, (batch_size, *image_size))
return (images+1)/2.0
mnist_trainset=mnist['train']
mnist_trainset=mnist_trainset.map(lambda ex:preprocess(ex, mode=mode_z))
mnist_trainset=mnist_trainset.shuffle(10000)
mnist_trainset=mnist_trainset.batch(batch_size, drop_remainder=True)
with tf.device(device_name):
gen_model=make_generator_network(
num_hidden_layers=gen_hidden_layers,
num_hidden_units=gen_hidden_size,
num_output_units=np.prod(image_size))
gen_model.build(input_shape=(None, z_size))
disc_model=make_discriminator_network(
num_hidden_layers=disc_hidden_layers,
num_hidden_units=disc_hidden_size)
disc_model.build(input_shape=(None, np.prod(image_size)))
loss_fn=tf.keras.losses.BinaryCrossentropy(from_logits=True)
g_optimizer=tf.keras.optimizers.Adam()
d_optimizer=tf.keras.optimizers.Adam()
all_losses=[]
all_d_vals=[]
epoch_samples=[]
start_time=time.time()
for epoch in range(1, num_epochs+1):
epoch_losses, epoch_d_vals=[], []
for i, (input_z, input_real) in enumerate(mnist_trainset):
with tf.GradientTape() as g_tape:
g_output=gen_model(input_z)
d_logits_fake=disc_model(g_output, training=True)
labels_real=tf.ones_like(d_logits_fake)
g_loss=loss_fn(y_true=labels_real, y_pred=d_logits_fake)
g_grads=g_tape.gradient(g_loss, gen_model.trainable_variables)
g_optimizer.apply_gradients(grads_and_vars=zip(g_grads, gen_model.trainable_variables))
with tf.GradientTape() as d_tape:
d_logits_real=disc_model(input_real, training=True)
d_labels_real=tf.ones_like(d_logits_real)
d_loss_real=loss_fn(y_true=d_labels_real, y_pred=d_logits_real)
d_logits_fake=disc_model(g_output, training=True)
d_labels_fake=tf.zeros_like(d_logits_fake)
d_loss_fake=loss_fn(y_true=d_labels_fake, y_pred=d_logits_fake)
d_loss=d_loss_real+d_loss_fake
d_grads=d_tape.gradient(d_loss, disc_model.trainable_variables)
d_optimizer.apply_gradients(grads_and_vars=zip(d_grads, disc_model.trainable_variables))
epoch_losses.append((g_loss.numpy(), d_loss.numpy(), d_loss_real.numpy(), d_loss_fake.numpy()))
d_probs_real=tf.reduce_mean(tf.sigmoid(d_logits_real))
d_probs_fake=tf.reduce_mean(tf.sigmoid(d_logits_fake))
epoch_d_vals.append((d_probs_real.numpy(), d_probs_fake.numpy()))
all_losses.append(epoch_losses)
all_d_vals.append(epoch_d_vals)
print('에포크 {:03d} | 시간 {:.2f} min | 평균 손실 >> 생성자/판별자 {:.4f}/{:.4f} [판별자-진짜: {:.4f}] 판별자-가짜: {:.4f}]'.format(epoch, (time.time()-start_time)/60, *list(np.mean(all_losses[-1], axis=0))))
epoch_samples.append(create_samples(gen_model, fixed_z).numpy())
get Graph
import itertools
import matplotlib.pyplot as plt
import numpy as np
fig=plt.figure(figsize=(16, 6))
ax=fig.add_subplot(1, 2, 1)
g_losses=[item[0] for item in itertools.chain(*all_losses)]
d_losses=[item[1] for item in itertools.chain(*all_losses)]
plt.plot(g_losses, label='Generator loss', alpha=0.95)
plt.plot(d_losses, label='Discriminator loss', alpha=0.95)
plt.legend(fontsize=20)
ax.set_xlabel('Iteration', size=15)
ax.set_ylabel('Loss', size=15)
epochs=np.arange(1, 101)
epoch2iter=lambda e: e*len(all_losses[-1])
epoch_ticks=[1, 20, 40, 60, 80, 100]
newpos=[epoch2iter(e) for e in epoch_ticks]
ax2=ax.twiny()
ax2.set_xticks(newpos)
ax2.set_xticklabels(epoch_ticks)
ax2.xaxis.set_ticks_position('bottom')
ax2.xaxis.set_label_position('bottom')
ax2.spines['bottom'].set_position(('outward', 60))
ax2.set_xlabel('Epoch', size=15)
ax2.set_xlim(ax.get_xlim())
ax.tick_params(axis='both', which='major', labelsize=15)
ax2.tick_params(axis='both', which='major', labelsize=15)
ax=fig.add_subplot(1, 2, 2)
d_vals_real=[item[0] for item in itertools.chain(*all_d_vals)]
d_vals_fake=[item[1] for item in itertools.chain(*all_d_vals)]
plt.plot(d_vals_real, alpha=0.75, label=r'Real: $D(\mathbf{x}$')
plt.plot(d_vals_fake, alpha=0.75, label=r'Fake: $D(G(\mathbf{z}))$')
plt.legend(fontsize=20)
ax.set_xlabel('Iteration', size=15)
ax.set_ylabel('Discriminator output', size=15)
ax2=ax.twiny()
ax2.set_xticks(newpos)
ax2.set_xticklabels(epoch_ticks)
ax2.xaxis.set_ticks_position('bottom')
ax2.xaxis.set_label_position('bottom')
ax2.spines['bottom'].set_position(('outward', 60))
ax2.set_xlabel('Epoch', size=15)
ax2.set_xlim(ax.get_xlim())
ax.tick_params(axis='both', which='major', labelsize=15)
ax2.tick_params(axis='both', which='major', labelsize=15)
plt.show()
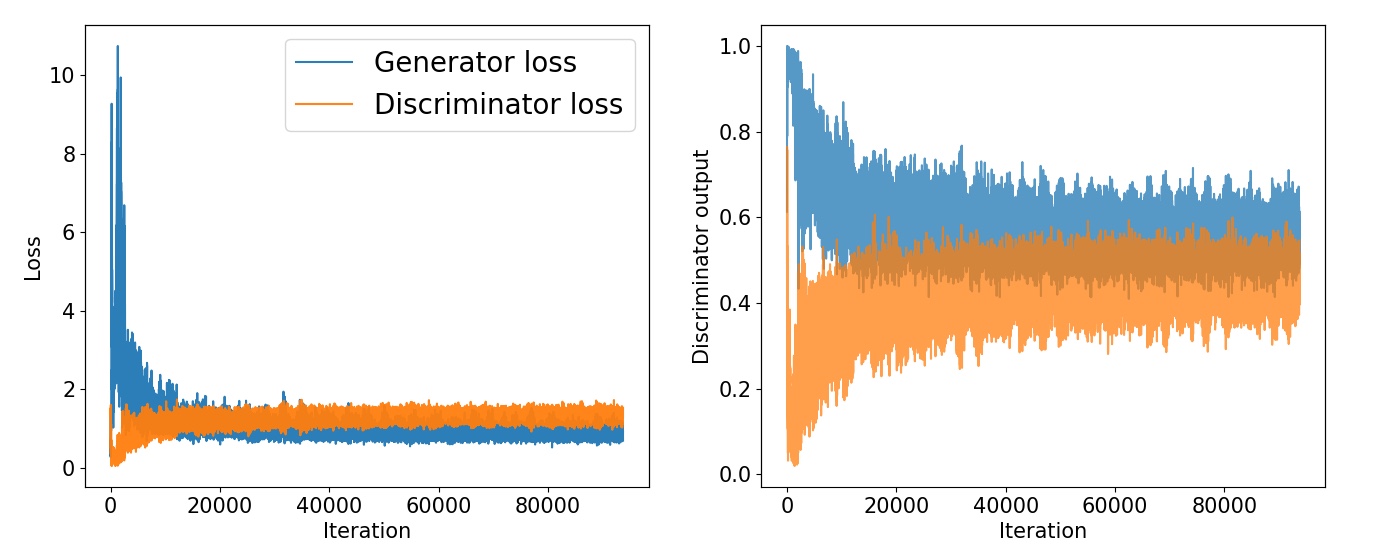
훈련초기에는 판별자가 진짜와 가짜 샘플을 매우 정확하게 구별하는 법을 빠르게 학습한다.
(가짜 샘플의 확률이 0에 가까움)
훈련이 진행됨에 따라서, 생성자가 진짜와 같은 이미지를 생성하기 때문에
진짜와 가짜 샘플에 대한 확률이 0.5에 가까워진다.
from epoch_sampels get images
selected_epochs=[1, 2, 4, 10, 50, 100]
fig=plt.figure(figsize=(10, 14))
for i, e in enumerate(selected_epochs):
for j in range(5):
ax=fig.add_subplot(6, 5, i*5+j+1)
ax.set_xticks([])
ax.set_yticks([])
if j==0:
ax.text(-0.06, 0.5, 'Epoch {}'.format(e), rotation=90, size=18, color='red', horizontalalignment='right', verticalalignment='center', transform=ax.transAxes)
image=epoch_samples[e-1][j]
ax.imshow(image, cmap='gray_r')
plt.show()

훈련이 진행될 수록 더 실제 같은 이미지를 만든다. 100번째 에포크의 미지는 MNIST 데이터셋의 글자와 매우 다르다.
이는 위의 GAN 모델은 생성자와 판별자 신경망이 완전 연결 은닉층 하나만 가지는 단순한 GAN 모델이기 때문이다.
CNN(Convolutional Neural Network)의 이미지 분류에서의 장점을 이용하면, 더 강력한 GAN 모델을 만들 수 있다.